https://mizu.re/post/exploring-the-dompurify-library-bypasses-and-fixes
Exploring the DOMPurify library: Bypasses and Fixes (1/2). Tags:Article - Article - Web - mXSS
Exploring the DOMPurify library: Bypasses and Fixes (1/2) 📜 Introduction This article will be part of a two-article series focusin📜 Introductionel free to skip to "DOMPurify 3.1.0 bypass (found by @IceFont 👑)". 🔍 How does client-side HTML sanit
mizu.re
클라이언트 측 HTML 정화기는 어떻게 작동하는가?
기술적인 세부사항으로 들어가기 전에, 클라이언트 측 HTML 정화기가 어떻게 작동하는지를 간단히 설명하는 것이 중요하다고 생각합니다. 본질적으로 기억해야 할 점은, 클라이언트 측 정화기를 사용하면 브라우저의 HTML 파서를 활용하게 되므로 파싱 방식의 차이(parsing differentials)가 발생할 가능성이 줄어든다는 것입니다. 예를 들어, 클라이언트 측 HTML 정화기를 사용할 경우, 설계상 잘못된 주석(comment) 파싱과 관련된 문제는 영향을 미치지 않는데, 어차피 동일한 HTML 파서를 두 번 사용하기 때문입니다.
package main
import (
"fmt"
"github.com/microcosm-cc/bluemonday"
)
func main() {
unsafeHTML := `<!--><img src=x onerror=alert()>>`
p := bluemonday.NewPolicy()
p.AllowComments()
safeHTML := p.Sanitize(unsafeHTML)
fmt.Println("Sanitized HTML:", safeHTML) // <!--><img src=x onerror=alert()>-->
}그림 1: Golang의 bluemonday HTML 정화기에서 발견된 우회 취약점 — x/net/html에서의 HTML 주석 파싱 불일치로 인해 발생한 것으로, @gregxsunday가 발견했습니다 (참조).
이 문제를 직접 쉽게 재현해보고 싶다면, pybluemonday 버전 0.0.9 이하를 사용하면 됩니다. 이 버전들은 모두 이 취약점이 포함된 취약한 버전입니다. 클라이언트 측 HTML 정화기가 내부적으로 어떻게 작동하는지에 대한 예시로, DOMPurify의 작동 흐름을 단순화한 버전을 소개합니다. 이 글에서는 DOMPurify를 중심으로 다루기 때문입니다 :)

- _initDocument: 브라우저처럼 HTML을 파싱하기 위해 DOMParser API를 사용합니다.
- _createNodeIterator: NodeIterator를 사용하여 DOM 트리를 순회합니다.
- _sanitizeElements: DOM Clobbering, mXSS 등의 공격을 검사하고 현재 태그가 허용된 것인지 확인합니다.
- _sanitizeShadowDOM: NodeIterator API는 기본적으로 <template> 태그 내부를 순회하지 않기 때문에, DocumentFragment에 도달했을 때 재귀적으로 정화합니다.
- _sanitizeAttributes: DOM API를 이용해 HTML 속성을 정화합니다.
- body.innerHTML: 정화된 HTML을 문자열로 직렬화하여 반환합니다.
이 내용은 DOMPurify의 로직을 매우 단순화한 버전입니다. 모든 보안 메커니즘을 제대로 이해하고 싶다면, 직접 소스 코드를 읽어보는 것을 추천합니다.
왜 mutation XSS(mXSS)가 가능한가?
이전 섹션을 바탕으로, 여러분은 아마 이렇게 생각할 수 있습니다:
브라우저와 동일한 파서를 사용하는 클라이언트 측 정화기(sanitizer)가 어떻게 우회될 수 있지?
좋은 질문입니다. 그리고 이 문제는 HTML이 작동하는 방식 때문에 대부분 발생합니다.
그 첫 번째 이유는, HTML 명세서(specification)에서도 잘 설명되어 있듯이: HTML 문자열을 두 번 파싱하면, 그 결과가 매번 다를 수 있기 때문입니다.
@SecurityMB가 DOMPurify 2.0.17 미만 버전을 우회하기 위해 사용한 "잘 알려진" 예시 중 하나는 <form> 요소의 자식 제한과 관련이 있습니다. 이 제한은 <form> 안에 또 다른 <form>을 중첩하는 것을 막습니다.

그림 5: <form> 요소의 파싱 속성을 이용한 이중 파싱 변조.
상단의 문자열은 수동으로 편집할 수 있으며, 그 결과는 하단에 표시됩니다. 이 도구는 ‘파이프라인(pipelines)’ 방식을 사용하며, 여기서 우리는 DOMParser 메서드를 이용한 이중 HTML 파싱 결과를 볼 수 있습니다. @BitK_ 님이 제작한 이 뛰어난 인터랙티브 DOM 트리 렌더링 도구에 감사드립니다. 또한, 문자열로부터 HTML DOM 트리를 파싱할 때는, 각 태그를 어떻게 해석해야 하는지에 대한 여러 규칙이 존재합니다. HTML 명세서에 정의된 이러한 규칙 중 일부는 네임스페이스(namespace)라는 개념과 관련되어 있습니다.
- <html> → HTML 네임스페이스
- <svg> → SVG 네임스페이스
- <math> → MathML 네임스페이스
이 각각의 네임스페이스는 고유한 파싱 규칙을 가지고 있기 때문에, 같은 태그라도 문맥에 따라 전혀 다르게 해석될 수 있습니다. 이것이 클라이언트 측에서도 HTML 정화가 복잡해지는 핵심 이유 중 하나입니다. 예를 들어, <style> 요소는 HTML 네임스페이스에서는 텍스트로 처리되지만, MathML이나 SVG 네임스페이스 안에서는 HTML로 처리됩니다.
그림 6: HTML 네임스페이스에서의 <style> 요소 파싱.
그림 7: SVG 네임스페이스에서의 <style> 요소 파싱.
위의 두 동작은 SVG 및 MathML 네임스페이스에서 HTML 네임스페이스로 전환하기 위해 HTML 통합 지점(HTML integration points) 및 MathML 텍스트 통합 지점(MathML text integration points)과 함께 사용됩니다.
MathML 텍스트 통합 지점 목록:
- <mi>
- <mo>
- <mn>
- <ms>
- <mtext>
HTML 통합 지점 목록:
- <annotation-xml>
- <foreignObject>
- <desc>
- <title>
그림 8: HTML 통합 지점 사용 예시.
이미 많은 고급 mutation 기법들이 훌륭한 연구자들에 의해 발견되고 문서화되었습니다. 모든 mutation 기법과 그 잠재적인 위험성을 하나하나 설명하기에는 너무 방대하므로, 아직 확인하지 않으셨다면 아래의 자료들을 참고하시길 추천드립니다(아마 훌륭한 자료들을 많이 빠뜨렸을 수도 있습니다).
이제 다음 섹션들을 이해하는 데 필요한 모든 정보를 갖추었으니,본격적으로 우회 기법(bypass)에 대해 이야기해봅시다.
DOMPurify 3.1.0 우회 (발견자: @IceFont 👑)
최근 DOMPurify 연구에 대한 간략한 배경 설명입니다. 이야기는 2024년 4월 26일, @cure53berlin이 DOMPurify 버전 3.1.0 이하에서 전체 우회(full bypass)가 가능하다는 내용을 게시하면서 시작됩니다. 이 취약점은 @IcesFont가 발견한 것입니다.
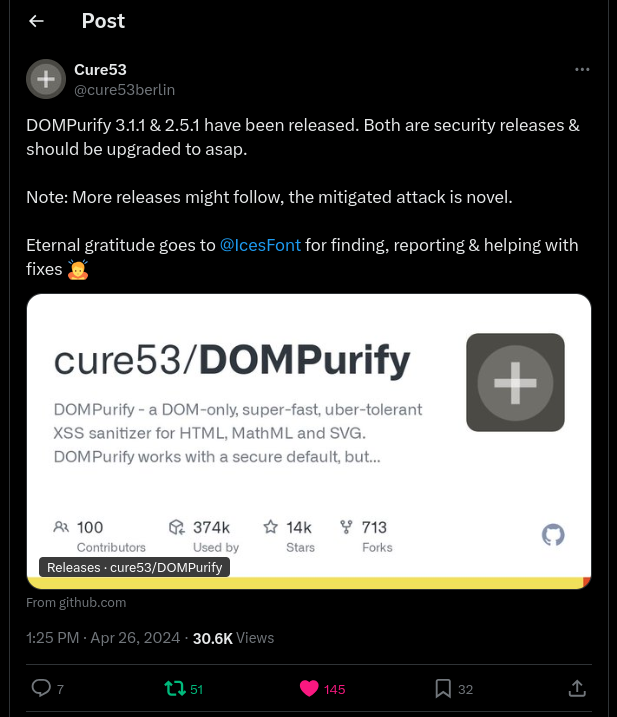
이번 우회는 여러 가지 새로운 mutation 개념들이 포함되어 있어, 재현하기가 매우 어려웠습니다. 다행히도 @IcesFont가 자신의 우회 방식에 대해 더 많은 세부 정보를 친절히 공유해 주었고, 그 덕분에 제 이해가 크게 향상되었습니다 ❤️
제가 DOMPurify 3.1.1과 3.1.2 버전에서도 우회를 발견할 수 있었던 것은 전적으로 @IcesFont의 연구 덕분이라는 점을 꼭 강조하고 싶습니다. 이제, @IcesFont가 DOMPurify ≤ 3.1.0을 기본 설정에서 어떻게 우회했는지 본격적으로 살펴보겠습니다 :D
노드 평탄화(Node flattening)
HTML 트리를 파싱할 때 고려해야 할 요소는 매우 많습니다.
그중 쉽게 떠오르지 않을 수 있는 한 가지는 바로:
DOM 트리는 얼마나 깊어질 수 있을까?
라는 질문입니다. 흥미롭게도, HTML 명세는 이와 관련하여 명확한 가이드라인을 제공하지 않습니다. 즉, 트리의 깊이에 따른 제한이나 처리 방식은 브라우저 구현에 따라 다를 수 있으며, 이로 인해 예기치 못한 DOM 구조 변경이나 mutation XSS의 기회를 만들 수 있습니다.

이러한 이유로, 각 HTML 파서 구현체는 자체적인 제한을 정의할 수 있으며, 해당 제한에 도달했을 때 서로 다른 방식으로 동작할 수 있습니다. 이로 인해 파싱 불일치(parsing discrepancies)의 위험이 크게 증가하게 됩니다.
| Language | Library | Nested node limit | Handling |
| Chromium | DOMParser | 512 | Flattening |
| Firefox | DOMParser | 512 | Flattening |
| Safari | DOMParser | 512 | Flattening |
| Ruby | nokogiri (updated version of libxml2) | 256 | Removing |
| C | libxml2 | 255 | Removing |
| PHP | php-xml (libxml2) | 255 | Removing |
| Python | lxml (libxml2) | 255 | Removing |
| Python | html.parser | No limit? | - |
| javascript | parse5 | No limit? | - |
| javascript | htmlparser2 | No limit? | - |
| Golang | x/net/html | No limit? | - |
| Rust | html5ever | No limit? | - |
| Java | Jsoup | No limit? | - |
| Perl | HTML::TreeBuilder | No limit? | - |
그림 11: HTML 파서에 따른 중첩 노드 제한 처리 방식.
예를 들어, 이것은 현재 사용 중인 브라우저가 이 상황을 처리하는 방식입니다: (제가 틀리지 않았다면, 그리고 해당 동작이 변경되지 않았다면, 출력 결과는 다를 것입니다. 그렇지 않다면 트위터 DM으로 알려주세요!)
그림 12: 깊이 511의 중첩 노드.
그림 13: 깊이 512의 중첩 노드.
이 동작이 mXSS 관점에서 더욱 흥미로운 이유 중 하나는, 이 변형(mutation)이 발생하는 시점과 관련이 있습니다. 위의 실시간 예제들에서 볼 수 있듯이, <style> 태그가 <svg> 태그 바깥으로 평탄화(flattening)되더라도, 여전히 SVG 네임스페이스에 속해 있는 상태입니다. 이것은 해당 노드가 파싱된 이후에 평탄화가 발생한다는 것을 강하게 시사합니다. 그 결과, “잘못된(invalid)” HTML DOM 트리를 생성하는 것이 가능해지며, 이를 직렬화하고 다시 파싱하면 또 다른 mutation이 발생할 수 있습니다. 예를 들어, HTML 네임스페이스에서 <a> 태그가 또 다른 <a> 태그의 자식이면, 브라우저는 이를 꺼내어(pop out) 트리에서 올바르게 정리합니다. 하지만, SVG 네임스페이스에서 평탄화된 <a> 태그가 HTML 네임스페이스로 넘어온 경우에는 꺼내지지 않고 그대로 유지됩니다!
그림 14: 평탄화되지 않은 중첩 <a> 태그.
그림 15: 평탄화된 중첩 <a> 태그.
정화기(sanitizer)에서 “잘못된(invalid)” HTML을 반환할 수 있다는 것은 매우 강력한 mutation 도구(gadget)입니다. 왜냐하면 대부분의 경우, 이를 다시 파싱하면 mutation이 발생하기 때문입니다.
HTML 파싱 상태
이제 마지막으로 살펴볼 부분은, HTML 파싱 상태가 어떻게 처리되는지에 대한 깊은 이해가 필요합니다. 이번 우회 기법에서는 두 가지 개념에 집중할 것입니다: 바로 HTML 삽입 모드(HTML insertion modes)와 열린 요소 스택(stack of open elements)입니다. HTML 명세에 따르면, 삽입 모드는 HTML 문자열을 파싱할 때 토큰이 처리되는 방식을 정의하기 위한 것입니다.

삽입 모드(Insertion Mode)는 HTML 파싱 과정 중 트리 구성 단계(tree construction stage)에서의 주된 동작을 제어하는 상태 변수(state variable)입니다. 초기에는 이 삽입 모드가 "initial" 상태로 설정됩니다. 이후 파싱이 진행되면서 아래와 같은 모드들로 전환될 수 있습니다: "before html" "before head" "in head" "in head noscript" "after head" "in body" "text" "in table" "in table text" "in caption" "in column group" "in table body" "in row" "in cell" "in select" "in select in table" "in template" "after body" "in frameset" "after frameset" "after after body" "after after frameset" 이 모드들은 파서가 토큰을 어떻게 처리할지, 그리고 CDATA 섹션을 허용할지 여부에 영향을 줍니다.
예를 들어, in caption 삽입 모드 정의에 따르면, 파서가 <caption> 시작 태그를 발견했을 때, 열린 요소 스택(stack of open elements)에서 <caption> 요소가 나올 때까지 요소들을 하나씩 제거(pop) 해야 합니다.
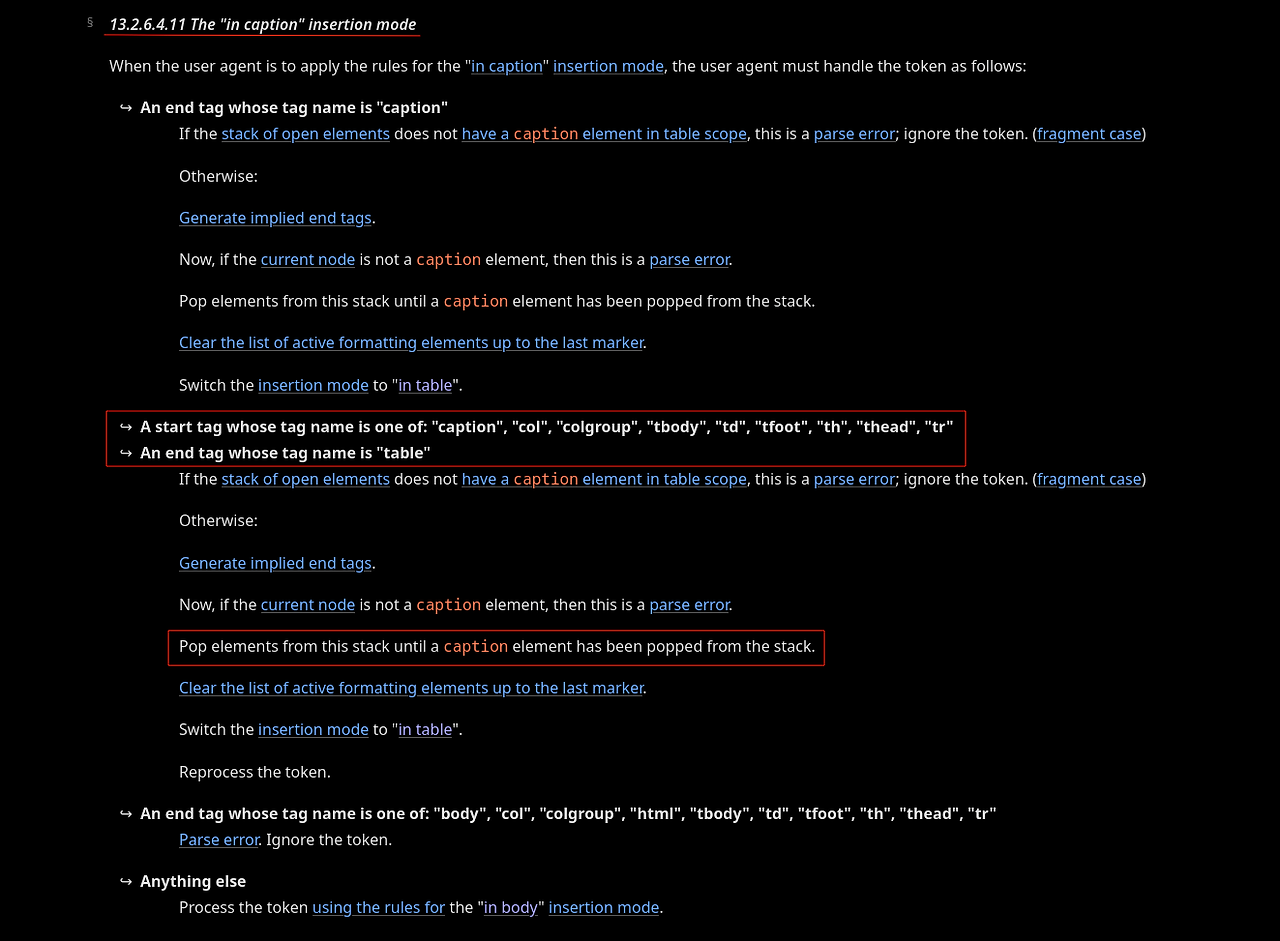
13.2.6.4.11 "in caption" 삽입 모드
사용자 에이전트가 "in caption" 삽입 모드의 규칙을 적용해야 할 때, 토큰은 다음과 같이 처리됩니다:
1. 종료 태그(end tag)**이고, 태그 이름이 "caption"인 경우:
1. 열린 요소 스택(stack of open elements)에 table scope 내에서 <caption> 요소가 존재하지 않는다면:
구문 오류(parse error)로 간주하고,이 토큰은 무시합니다(fragment 케이스).
2. 그렇지 않다면 (정상적인 <caption>이 스택에 존재하는 경우):
암시적 종료 태그(implied end tags)를 생성합니다.
그리고 현재 노드(current node)가 <caption> 요소가 아니면, 구문 오류입니다.
그런 다음, 스택에서 <caption> 요소가 나올 때까지 요소들을 하나씩 팝(pop) 합니다.
활성 서식 요소 목록(active formatting elements)을 마커(marker)가 나올 때까지 제거(clear)합니다.
마지막으로, 삽입 모드(insertion mode)를 "in table" 모드로 전환합니다.
2. **시작 태그(start tag)**의 태그 이름이 아래 목록 중 하나일 경우:
"caption", "col", "colgroup", "tbody", "td", "tfoot", "th", "thead", "tr"
또는, 종료 태그(end tag)**의 태그 이름이 "table"인 경우:
1. 열린 요소 스택(stack of open elements)에 table scope 내 <caption> 요소가 없다면:
구문 오류(parse error)로 간주해당 토큰을 무시합니다(fragment 케이스).
2. 그렇지 않은 경우 (정상적으로 <caption>이 존재하는 경우):
암시적 종료 태그(implied end tags)를 생성합니다.
현재 노드(current node)가 <caption> 요소가 아니라면 구문 오류(parse error)입니다.
열린 요소 스택에서 <caption> 요소가 나올 때까지 요소들을 팝(pop) 합니다.
활성 서식 요소 목록(active formatting elements)을 가장 최근의 마커(marker)까지 제거(clear)합니다.
삽입 모드(insertion mode)를 "in table"로 전환합니다.
그리고 이 토큰을 다시 처리(reprocess)합니다.
3. **종료 태그(end tag)**이고, 태그 이름이 다음 목록 중 하나인 경우:
"body", "col", "colgroup", "html", "tbody", "td", "tfoot", "th", "thead", "tr"
구문 오류(parse error)로 간주하고, 해당 토큰은 무시합니다.
4. 그 외의 모든 경우(Anything else):
"in body" 삽입 모드의 규칙을 사용하여 토큰을 처리합니다.
열린 요소 스택(stack of open elements)이란 무엇인가요?
본질적으로 이것은 LIFO(Last In, First Out) 구조의 HTML 요소 스택입니다. HTML 파서가 문자열을 처리하면서 새로운 태그를 열 때마다 이 스택에 추가(push)되고, 닫히는 태그를 만나면 스택에서 제거(pop)됩니다. 즉, 이 스택은 HTML 파싱 중 현재 열려 있는 태그들의 계층 구조를 추적하는 데 사용됩니다.

13.2.4.2 열린 요소 스택 (The stack of open elements)
초기에는 열린 요소 스택(stack of open elements)이 비어 있습니다. 이 스택은 아래 방향으로 확장됩니다. 스택의 맨 위(topmost) 노드는 가장 먼저 추가된 노드이고, 스택의 맨 아래(bottommost) 노드는 가장 최근에 추가된 노드입니다. 단, 잘못 중첩된 태그(misnested tags)를 처리할 때는 스택이 임의 접근(random access) 방식으로 조작될 수도 있습니다.

in caption 삽입 모드를 다시 살펴보면, 열린 요소 스택에서 <caption> 요소를 찾을 때까지 요소들을 제거(pop) 하게 되며, 그 결과로 중첩된 <caption> 아래에 있는 모든 요소들이 함께 제거됩니다. (비록 그 요소들이 해당 문맥에서 유효한 요소들이더라도 말이죠 :D)
그림 20: 중첩된 <caption> 태그의 경우에 대한 'in caption' 처리 예시
더 흥미로운 점은, 이 동작이 HTML 네임스페이스에 특화되어 있음에도 불구하고, 스택에서 제거(pop)되는 태그의 네임스페이스는 전혀 고려되지 않는다는 것입니다. 왜냐하면 이러한 태그들은 단순히 열린 요소 스택(stack of open elements)의 일부일 뿐이기 때문입니다.
그림 21: 중첩된 <caption>과 중첩된 SVG 네임스페이스 요소들이 있을 때의 in caption 처리 예시.
마지막으로, 이 상황을 노드 평탄화(node flattening)를 이용해 유도하기 위해 @IcesFont는 다음 사실을 활용했습니다:
in caption 삽입 모드는 결국 in body 삽입 모드로 폴백(fallback)되며,
이는 부모의 in table 삽입 모드를 "리셋"시키는 역할을 합니다.

그 토큰(EOF)을 "in body" 삽입 모드의 규칙에 따라 처리합니다.
그로 인해 <caption>을 중첩할 수 있는 유효한 컨텍스트(valid context)를 만들 수 있으며, 이를 통해 앞서 설명한 "잘못된(invalid)" 상황을 노드 평탄화(flattening)를 이용해 생성하는 것이 가능합니다 :D
그림 23: 평탄화 없이 in table 삽입 모드를 사용한 중첩 <caption> 파싱.
그림 24: 평탄화를 사용한 in table 삽입 모드에서의 중첩 <caption> 파싱.
Proof of Concept (POC)
이번 섹션에서 설명한 모든 내용을 종합하면, 다음과 같은 HTML 페이로드를 구성하여 DOMPurify ≤ 3.1.0을 우회할 수 있습니다️🔥
불행히도, Firefox는 <table> 태그가 두 번째 <caption> 태그와 같은 계층에 존재할 경우, DOM 구조를 변형(mutate)하지 않기 때문에 이 경우에는 취약하지 않습니다. 하지만, @kinugawamasato는 깊은 중첩(deep nesting)을 이용한 또 다른 mutation 기법을 발견했으며, 이 방식은 Firefox, Chromium, Safari 모두에서 작동합니다(다만 이 기법은 여기에서는 다루지 않습니다).
Dom-Explorer
yeswehack.github.io
그림 25: @IcesFont가 발견한 DOMPurify ≤ 3.1.0 우회 사례.
'모의해킹 리서치' 카테고리의 다른 글
| SQL Injection 리서치 : preparedStatement의 한계 (0) | 2025.11.11 |
|---|---|
| (한글번역) Exploring the DOMPurify library: Hunting for Misconfigurations [ 1 ] (3) | 2025.07.23 |
| (한글번역) Exploring the DOMPurify library : Bypasses and Fixes [ 2 ] (3) | 2025.07.23 |
| (한글번역) DoubleClickjacking : A New Era of UI Redressing (0) | 2025.07.06 |
| (한글번역) Account hijacking using “dirty dancing” in sign-in OAuth-flows (0) | 2025.04.29 |